存在即合理
正如明白了x += 1,就会尽量避免x = x + 1;
反观一搜一大把关于闭包的文章,无外乎只是告诉三点
- 晦涩难懂的概念
- 给几个简单的实例
- 结束
或许还会给个建议 少用
真的是这样么?
我搜索了大量的资料来写这篇文章,只是想尽力把自己说服、说明了。
下边有三到题目以及答案
- 如果你的预期和答案不符
- 如果你看不懂
- 如果你好奇的想一探究竟
请继续
否则就可以关闭这个文章了
文章长且内容多
# 第一题,是用来做什么的? |
# 第二题 |
# 第三题 |
答案
# 第二题 |
警示:认真的读下去,可能会花费你不少的时间
目标
- 掌握匿名函数
- 掌握高阶函数与匿名函数的用法
- 尽量搞明白闭包
第一部分 匿名函数
1 定义
lambda 函数也叫匿名函数,及即没有具体名称的函数,它允许快速定义单行函数,类似于 C 语言的宏,可以用在任何需要函数的地方。
lambda与def对比
| 区别 | def | lambda |
|---|---|---|
| 名称 | 有 | 无 |
| 返回值 | 函数对象但不给标识符 | 任意 |
| 作用 | 简单的 | 简单/复杂 |
| 作用范围 | 不能共享 | 可共享 |
2 表达式
# 函数 |
# 匿名函数 |
实现同样代码不同方式的实例:
# 函数 |
3 匿名函数与高阶函数
Python内置对数据处理的函数,效率比for要高,恰好,我们可以结合lambda函数,一块把二者学习了
# 罗列了常用的三种 |
简要介绍:
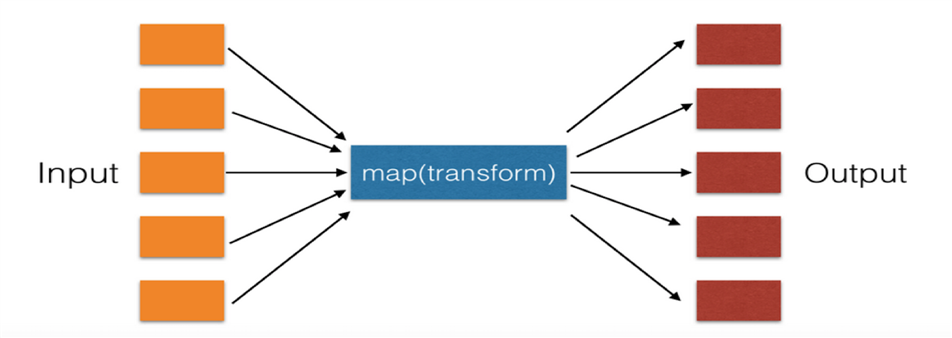
- map映射: 对iterable中的item依次执行function(item),执行结果输出为list
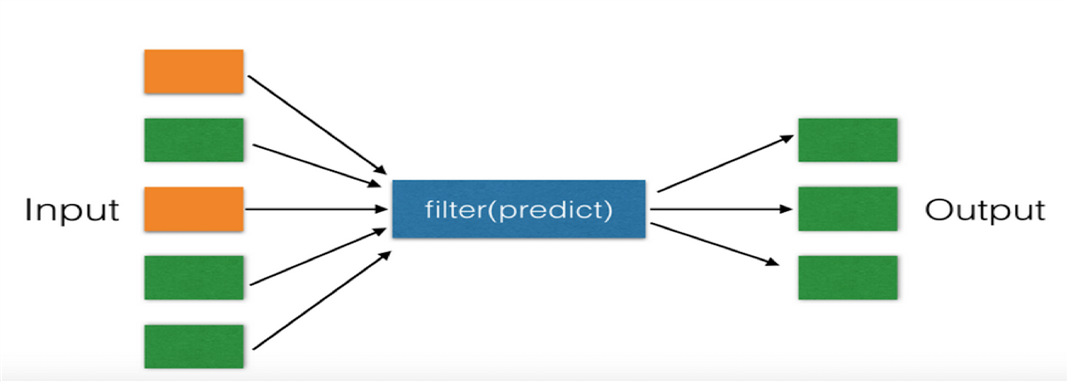
- filter过滤: 对iterable中的item依次执行function(item),将执行结果为True(!=0)的item组成一个List/String/Tuple(取决于iterable的类型)返回,False则退出(0),进行过滤。
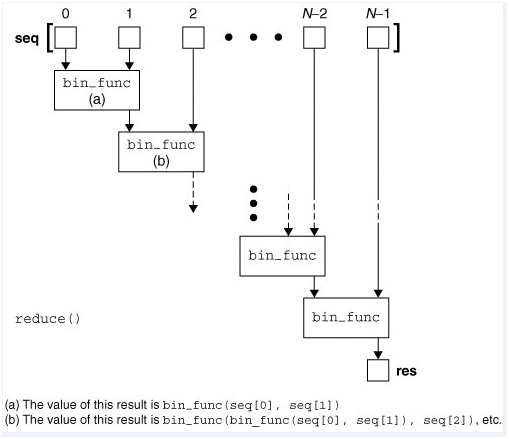
- reduce: iterable中的item顺序迭代调用function,函数必须要有2个参数。要是有第3个参数,则表示初始值,可以继续调用初始值,返回一个值
图解:

实例列表
# ------- map ------- # |
两个综合实例
这个就是开头的那个实例: 找出指定返回内的质子,涉及的内容有点多,包含之前章节中的推导式、range函数、函数、not等相关内容,试着先看下,是否能看明白。
# 质数的定义 只有1和它本身两个因数 |
试了下画个流程图,来作为补充,但是我怕画出来,更难理解了;
所以就用文字描述下,希望描述的清楚:
- 1 range(start, stop + 1) 生成
[)左闭右开的list_1数组 - 2 依次将list_1中的数【x】传给
匿名函数;【循环该操作】- 3 生成[2, x)的list_2
- 4 遍历list_2, 依次用
x%list_2[i]取余;*【循环该操作】** - 5 如果数组长度等于0,回到
2 - 6 如果余数等于0,返回余数,存进
list_new; - 7 等整个2走完,判断
list_new是否存在数据,得出当前x是否是质数,是否从list_1中过滤掉 - 8 进入list_1下一个元素的判断
先熟悉下not的用法,【在阶段汇总与补充中说明】
not [] |
下边这个求阶乘的,没啥难度,只要还记得
# 思考下这个,在思考下上边关于reduce的图例 |
# 计算 5!+4!+3!+2!+1! |
第二部分 闭包
接下来的内容涉及函数相关内容,之前的两篇文章
Python 基础系列–函数【9】
Python 基础系列之作用域【10】
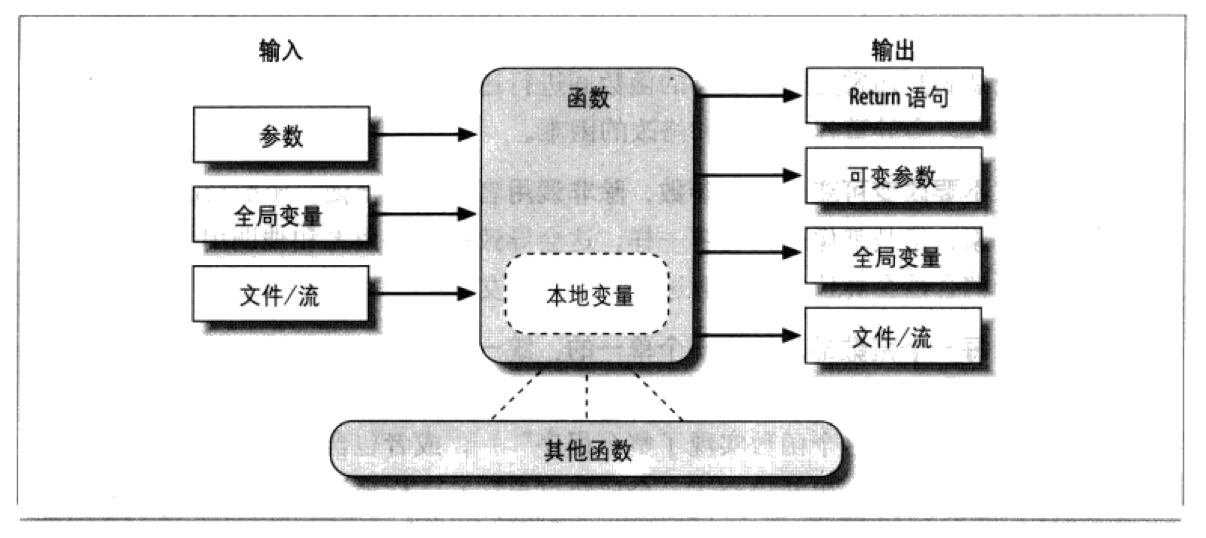
函数是对象,函数可以作为返回值,
在说闭包定义之前,我们先看下开头的那两段代码
1. 初始闭包
函数是对象,函数可以作为返回值。
# 第二题 |
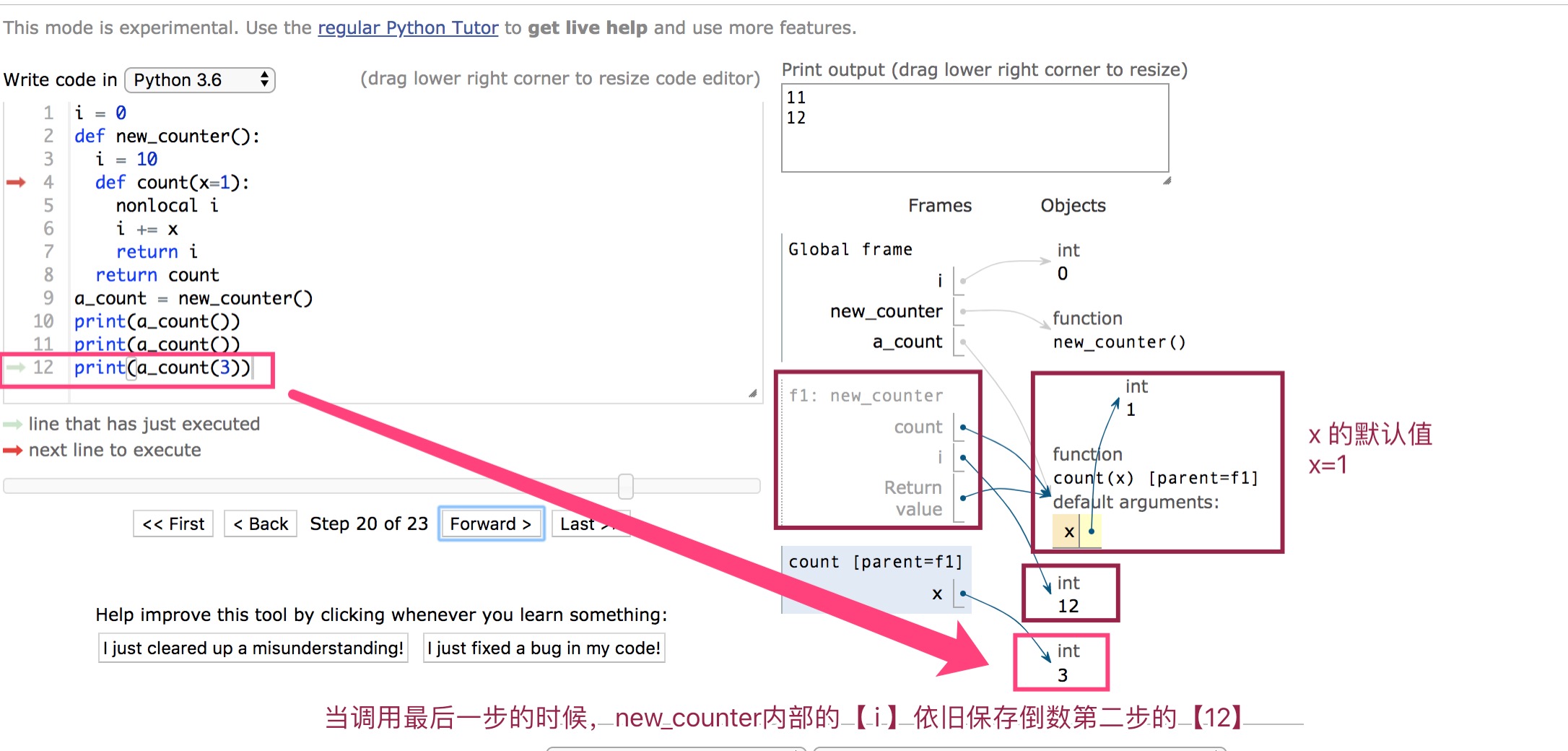
上侧的例子主要实现的是一个计数器的功能:每点击一次,在原基础上加1;
结合上图,大致了解下流程:
- 函数定于与返回:
- 外层函数new_counter返回了内层函数count作为结果;
- 内层函数count,中的参数:x有个默认值1;
- 内层函数count中的 i 利用了nonlocal,获取到10;
- a_count = new_counter()
- 将变量a_count指向new_counter()返回的count()
- count()的type为func,并且i持有10对应的内存地址
- 第一次调用a_count()时
- 没有参数,x默认为1;
- i持有10,经过➕后返回11
- 第二次调用a_count()时
- 没有参数,x默认为1;
- i持有11,经过➕后返回12
- 第二次调用a_count()时
- 没有参数,x=3;
- i持有12,经过➕后返回15
此时我不确定看了上图和说明,是否能够看懂闭包的用法
2 闭包的定义
比较晦涩的专业术语,但还是建议认真读读
都是大神发明的东西
真的很巧妙
下边的文字值得读 N 遍
维基百科上对闭包的解释就很经典:
在计算机科学中,闭包(Closure)是词法闭包(Lexical Closure)的简称,是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。
所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。 Peter J. Landin 在1964年将术语闭包定义为一种包含环境成分和控制成分的实体。
- 闭包概念:
- 闭包就是有权访问另一个函数作用域中变量的函数.
- 分析这句话:
- 闭包是定义在函数中的函数.
- 闭包能访问包含函数的变量.
- 闭包携带状态包
- 即使包含函数执行完了, 被闭包引用的变量也得不到释放.
接下来看第二个例子
3. 闭包的作用域
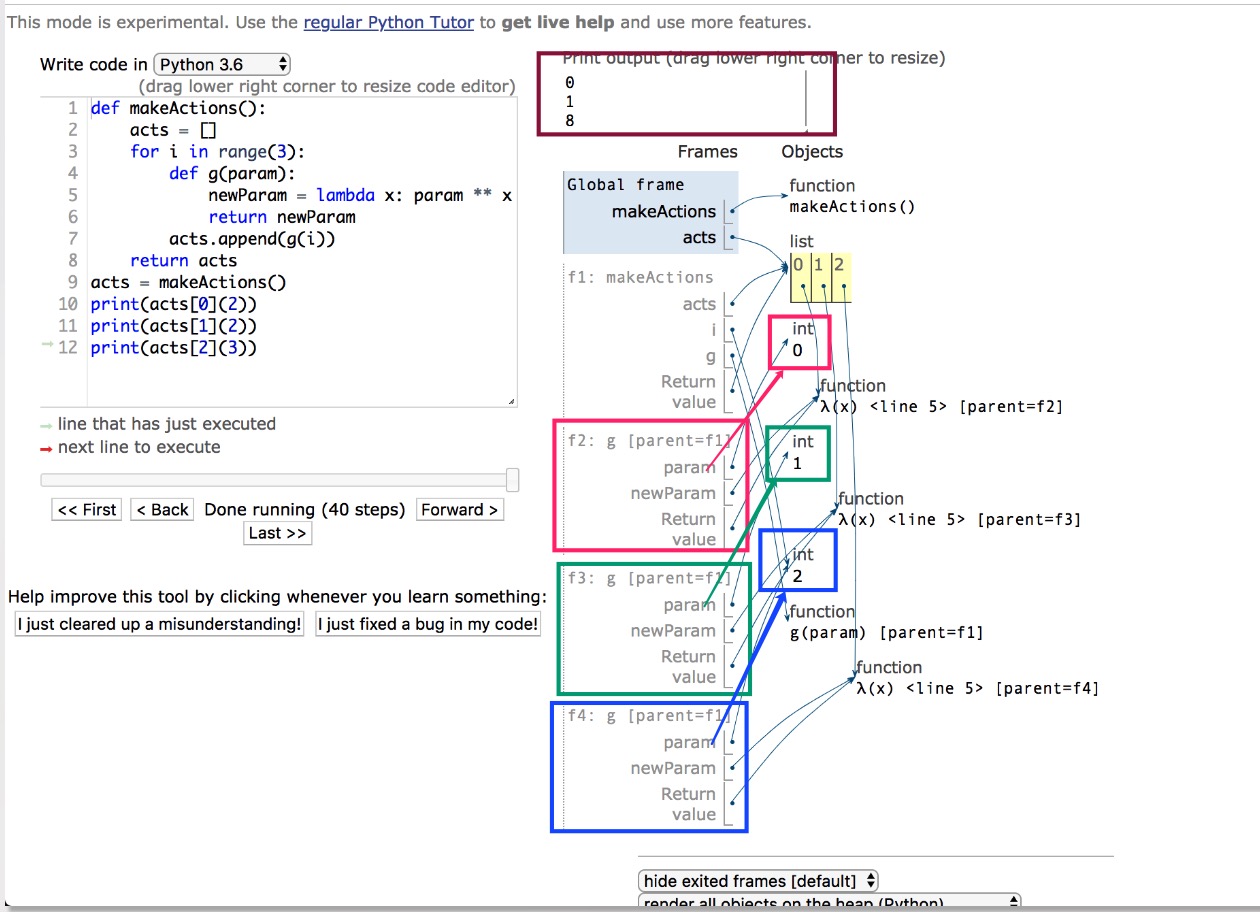
# 第三题 |
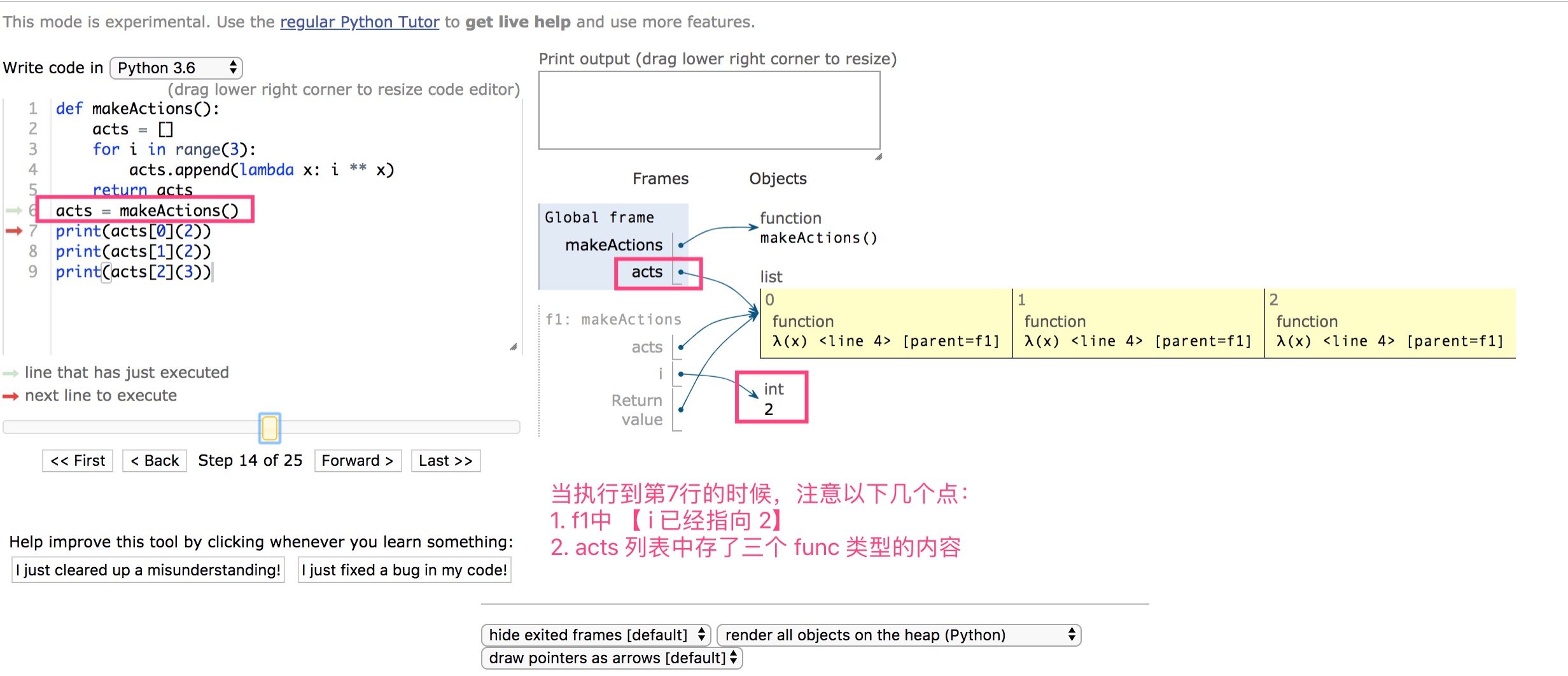
当执行结束acts = makeActions()这一行代码。
- makeActions()函数内部【i】持有了 2,并且不释放;
- acts实际包含了三个函数类型的内容
- 当调用
acts[x](2), 实际执行函数为lambda x: i ** x,而i持有2 - 故当 y 一致时,x 的位置变化不影响结果,(acts[x] (y))
4 加深一点
如果我们就是要错误的结果,【0,1,8】呢?
如何去实现?
还记得在前面🈶个状态的概念吗?
- 携带状态的闭包的概念
- 即使包含函数执行完了, 被闭包引用的变量也得不到释放.
思路:假如我们把列表中的位置对应i的状态保存起来,那就不就完事了么?
如果真的从头看到现在,并且一路思考,想必已经花费你不少时间了。
此时的你应该完全理解文中阐述的内容了。
相对真正掌握知识而言,付出的时间的价值是翻倍的
def makeActions(): |
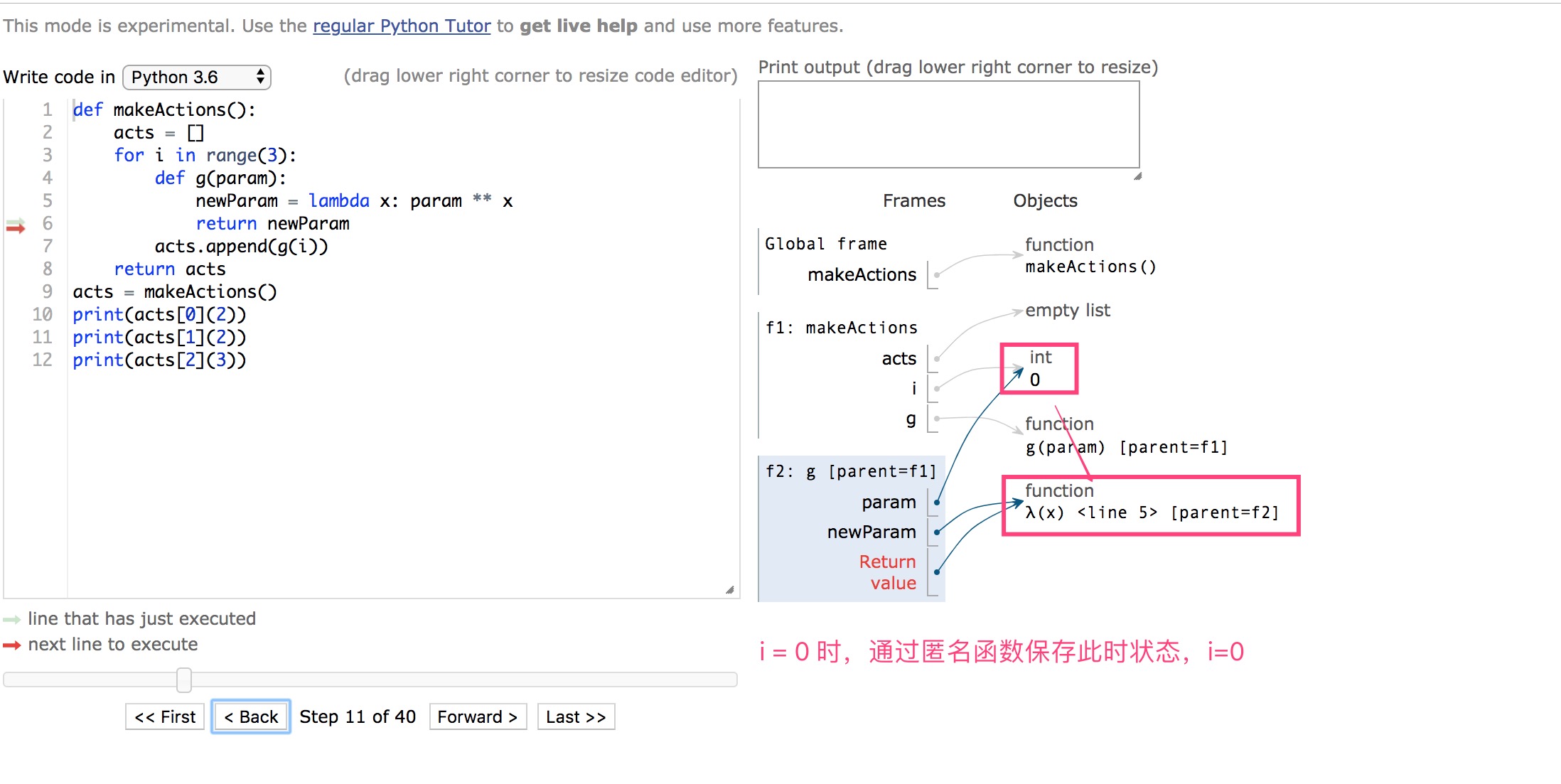
5 再深入一些
这段代码能让你想到什么❓
最直观的就是:这个是个闭包
但是:这段代码万万不能让我联想到:直线方程、斜率、截距、坐标系等等的概念。
# 第一种写法 |
当我们明白了:函数是对象、函数可以作为返回值、闭包携带状态等等的概念后,可能会思考
- 为何会有这种东西存在❓
- 究竟其用途是什么❓
关于这个疑问,在所搜大量数据的时候,发现了知乎上有个有意思的问答
简短答案:前者更具有可读性和可移植性。
较完整答案:闭包(closure)和类(class)有相通之处,带有面向对象的
封装思维。而面向对象编程正是为了更佳的可读性和更关键的可移植性;不过这个例子没太体现出面向对象的额外优势。升级答案:题主问出这个问题,很可能是现在
流行的编程教材知其然不知其所然的风格带来的恶果。如果未来带着这个想法进入IT行业,会非常不适应公司的代码规范等基础要求;即便不入行只是自己写写程序用,也会和很多优秀、可复用等的理念失之交臂。我认为一本优秀的教材除了讲基础语法,应该尽量教你代码
为什么这么写好、那么写不好、那么那么写现在能用但多半以后会出事。